




روزانه سایتهای بیشماری توسط رباتهای گوگل و موتورهای جستجوگر دیگر بررسی و ایندکس میشوند. اکثر این رباتها برای خزیدن در سایتها به نقشه راه و مسیرهای ممنوعه نیاز دارند. فایل robots.txt اولین فایلی است که به استقبال این رباتها میرود. اما فایل robots.txt چیست؟ فایل robots.txt چه کاربردی در سئو سایت دارد؟ محل قرارگیری و دستورات قابل اجرای آن چیست؟ با آموزش سئو میتوانید به تمامی این سوالات در مورد robots.txt و اهمیت آن در سئو پاسخ دهید.
فایل robots.txt چیست؟
به فایلی که از مجموعه دستوراتی مختلف برای رباتها تشکیل شده است؛ robots.txt میگویند. فایل robots.txt سایت در Root Directory یا مسیر اصلی سایت قرار میگیرد. از کاربرد عمده این فایلها میتوان به مدیریت فعالیتهای رباتها و خزندههای خوب اشاره کرد. زیرا رباتهایی که فعالیتهای مخرب انجام میدهند پیرو این دستورات نیستند.
فایل robots.txt همانند یک آییننامه اخلاقی در بستر اینترنت و برای رباتها است. رباتهای خوب موارد ذکر شده در آییننامه را رعایت میکنند اما رباتهای بد نسبت به آنها بی توجهاند. این رباتها به احتمال زیاد از دستورات تعریف شده سرپیچی میکنند و بن میشوند. اما سوال اصلی آن است که فایل robots.txt چیست؟
| دستورات robots.txt |
|---|
| User-agent |
| Allow |
| Disallow |
| Crawl-delay |
| Sitemap |
این فایل با استفاده از دستورات نوشته شده در خود، خزندههای موتور جستجوگر را مطلع میکنند تا به گروهی از صفحات سایت مراجعه نکنند. اکثر موتورهای جستجو مانند گوگل، Bing و یاهو دستورات این فایل را تشخیص میدهند.

فایل robots.txt چه کاربردی در سئو سایت دارد و چگونه کار میکند؟
Robots.txt تنها یک فایل متنی ساده با پسوند “.txt” بوده و نشانهگذاری Html ندارد. این فایلها بر روی هاست سایتها آپلود میشوند و هیچ پیوندی با بخشهای دیگر سایت ندارند. کاربران عادی در حالت عادی برخوردی با این فایل نخواهند داشت. اما اولین فایلی که رباتها هنگام خزیدن و ایندکس کردن سایتها بررسی میکند؛ فایل robots.txt است.
رباتهای موجود در بستر اینترنت به دو دسته خوب یا بد تقسیم میشوند. رباتهای خوب در اولین گام دستورات robots.txt را بررسی میکنند و بر اساس آنها بخشهای قابل دسترس را ایندکس میکنند. رباتهای مخرب یا بد برخلاف رباتهای خوب، نه تنها این فایل را نادیده گرفته، به دستورات آن نیز عمل نمیکنند.
به خاطر داشته باشید که همه زیردامنهها یا ساب دامینهای یک سایت به ایجاد و تنظیم robots.txt نیاز دارند. به عنوان مثال سایت www.seo.com فایل مخصوص به خود را داشته و زیر مجموعههای آن نیز مانند blog.seo.com، community.seo.com نیاز به فایل مختص به خود را دارند.

اهمیت وجود فایل robots.txt
همانطور که مطالعه کردید در بستر اینترنت دو نوع ربات خوب و بد وجود دارد. از نمونههای ربات خوب میتوان به خزندگان وب اشاره کرد. این رباتها با خزیدن در صفحات مختلف سایتها محتوای آن را در دسترس موتورهای جستجوگر قرار میدهند و صفحه آن را ایندکس میکند. این فایل متنی ساده با مدیریت رباتها از ایجاد ترافیک و شلوغ شدن سرور هاست سایت جلوگیری میکند.
برای درک اهمیت وجود این فایل باید به پاسخ سوال فایل robots.txt چه کاربردی در سئو سایت دارد؛ دست یابید.
بلاک کردن صفحات خصوصی
هر سایتی شامل صفحاتی بوده که از نظر سئو یا محتوا ارزش چندانی ندارد و نباید ایندکس شوند. به عنوان مثال وجود صفحه لاگین برای هر سایت ضروری بوده اما هر کسی نباید اجازه دسترسی به آن را داشته باشد. در این شرایط با استفاده از فایل robots.txt میتوانید از خزندگان سطح وب خواهش کنید که این صفحات را نادیده بگیرند و تنها بخشهای قابل دسترس را ایندکس کنند.
مدیریت و بهینه سازی Crawl Budget
اگر برای ایندکس شدن صفحات سایت خود دچار مشکل شدهاید؛ ممکن است از مشکلات بودجه خزش رنج ببرید. Crawl Budget به تعداد صفحاتی گفته میشوند که رباتهای گوگل در یک روز آنها را بررسی کرده و ایندکس میشوند. این عدد خود به عوامل دیگری وابسته بوده و با توجه به آنها تغییر میکند. عدم استفاده از این کاربرد فایل robots.txt میتواند ضررهای جبران ناپذیری برای عملکرد سایت به همراه داشته باشد.
شرایطی را تصور کنید که یک سایت دارای حجم بالایی از صفحات مختلف بوده و روزانه ترافیک بالایی توسط هزاران کاربر دارد. در صورت عدم استفاده از دستورات robots.txt ترافیک بالایی از رباتهای خزنده نیز به این آمار اضافه خواهد شد که میتوانند به عملکرد سایت آسیب وارد کند. با بلاک کردن یا از دسترس خارج کردن صفحاتی که از نظر سئو و کسب رتبه اهمیتی ندارند؛ ربات گوگل، زمان بیشتری را برای بررسی و ایندکس کردن بخشهایی که اهمیت بیشتری دارند؛ صرف میکند.
جلوگیری کردن از ایندکس شدن منابع سایت
علاوه بر فایل robots.txt دستورات Meta Directive یا متاتگها نیز میتوانند در مسدود کردن رباتهای خزنده نقش مهمی ایفا کنند. این دستورات همانند فایل متنی robots.txt از ایندکس شدن منابع و صفحاتی که ارزش بالایی ندارد، جلوگیری میکنند. اما از ضعف این دستورات میتوان به کار نکردن آنها برای مسدود کردن منابع چند رسانهای اشاره کرد. متاتگها نمیتوانند از ایندکس شدن فایلهایی مانند pdf و عکس جلوگیری کنند؛ بنابراین در این شرایط با تنظیم robots.txt از ایندکس شدن آنها جلوگیری کرد.

محل قرارگیری فایل robots.txt
فایل robots.txt سایت در مسیر Root Directory ذخیره میشود. برای پیدا کردن آن کافی است به صفحه cPanel سایت خود مراجعه کنید. در قسمت مدیریت فایل سی پنل میتوانید یک فایل با نام “public_html” پیدا کنید. حجم این فایل بسیار کم بوده و پس از باز کردن آن، با فایل متنی ساده رو به رو خواهید شد. اگر چنین فایلی را پیدا نکردید؛ باید یک فایل متنی ساده با نام “robots.txt” که حاوی دستورات مختلف است در مسیر اصلی سایت، آپلود کنید. هنگام ساخت فایل robots.txt دقت نمایید که نام آن با حروف کوچک نوشته شده باشد.
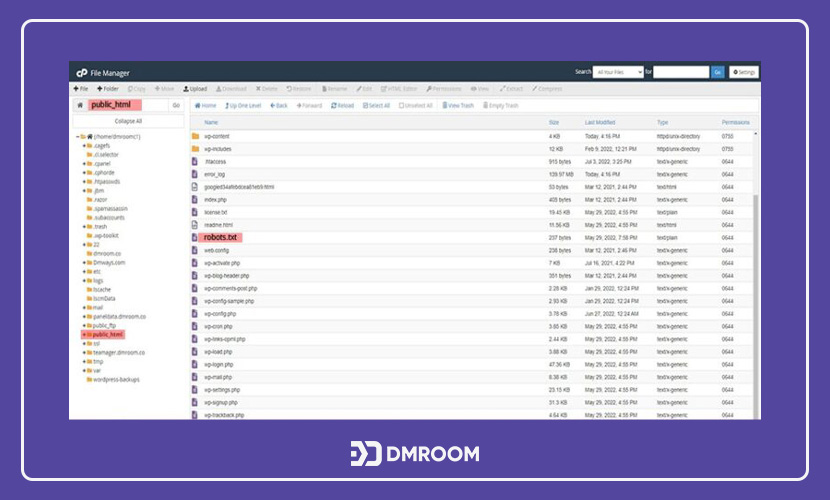
دستورات robots.txt
فایل robots.txt برای مشخص کردن بخشهای غیر قابل دسترس یک سایت نیاز به تعدادی دستورات پیش فرض دارد. از دستورات robots.txt میتوان به موارد زیر اشاره کرد.
- User-agent
- Allow
- Disallow
- Crawl-delay
- Sitemap

مفهوم و کاربرد “User-agent”
وبمسترها در فایل robots.txt میتوانند برای رباتهای مختلف، دستورالعملهای مختص به خود را تعریف کنند. به عنوان مثال فرد میخواهد یک صفحه مشخص در دسترس موتورهای جستجوگر گوگل باشد اما موتورهای Bing، به آن دسترسی نداشته باشند. برای انجام این کار کافی است که دو دستور با user-agent مختلف در نمونه فایل robots txt نوشته شود. یک دستور برای رباتهای گوگل و دیگری برای رباتهای Bing عمل خواهد کرد. نام رباتهای پرکاربرد موتورهای جستجوگر شامل موارد زیر میشود:
- Googlebot
- Googlebot-Image (برای تصاویر)
- Googlebot-News (مرتبط با اخبار)
- Googlebot-Video (ویژه ویدیوها)
- Bingbot (ربات موتور جستجوگر Bing)
- MSNBot-Media (برای ویدیو و تصاویر)
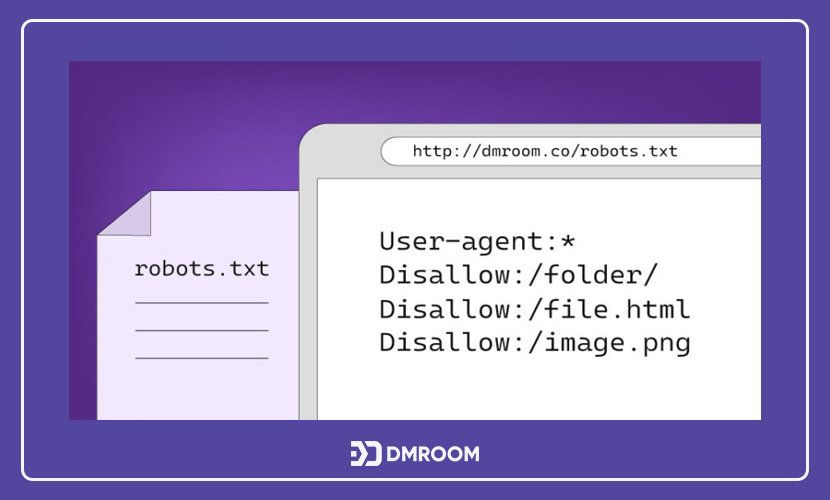
دستور “user-agent:*” در فایل robots txt
گاهی اوقات سئوکاران از برگ برنده خود استفاده کرده و با استفاده از این فایل، تمامی رباتها را برای دسترسی به بخشهای مختلف مسدود میکنند. برای انجام این کار کافی است که در نمونه فایل robots.txt در برابر دستور User-agent، علامت “*” را قرار دهند. این دستور به معنای آن است که اکثر رباتهای خزنده بستر وب، صفحه مشخص شده را نادیده خواهند گرفت.
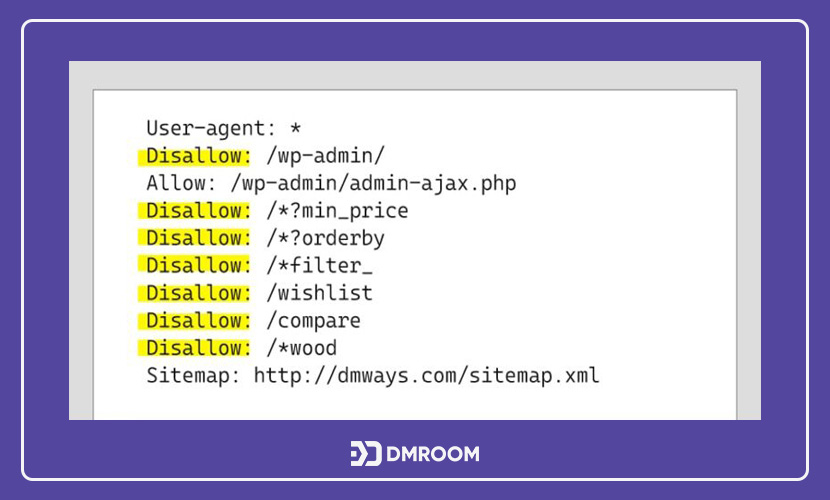
چگونگی عملکرد دستور “Disallow”
دستور disallow یکی از پرکاربردترین دستورات در فایل robots.txt است. بخشهایی از سایت که از دسترس رباتها خارج میشوند؛ برای کاربر مخفی نخواهد شد. اکثر اوقات کاربران میتوانند به این صفحات دسترسی پیدا کنند اگر از نحوه پیدا کردن آنها آگاه باشند.
دستور Disallow به چند روش مختلف در نمونه فایل robots txt قابل اجرا است. از مثالهای آن میتوان به موارد زیر اشاره کرد:
بلاک کردن یه صفحه
هنگامی که بخواهید یک مقاله یا یک صفحه از سایت خود را از دسترس خارج کنید؛ کافی است آدرس url آن را مقابل دستور Disallow قرار دهید. به عنوان مثال اگر آدرس صفحه مورد نظر شما www.seo.com/learning/what-is-robotstxt باشد؛ عبارتهای نوشته شده پس از دامنه اصلی، آدرس پیچ مورد نظر است.
Disallow: /learning/what-is-robotstxt/
با اعمال شدن این دستور، رباتهای خوب این صفحه را نادیده گرفته و ایندکس نمیشود.
بلاک کردن یک مسیر
گاهی اوقات مسدود کردن چند صفحه به صورت همزمان راهکاری مؤثرتر در مقایسه با مسدود کردن جداگانه آنها است. اگر صفحات مورد نظر در یک بخش قرار گرفته باشند؛ با استفاده از فایل robots.txt میتوان Root Directory مختص به آن را مسدود کرد. در این صورت رباتهای خزنده این مجموعه از صفحات وب را مورد بررسی قرار نخواهند داد.
دسترسی کامل
اگر میخواهید تمامی صفحات سایت قابل بررسی و ایندکس شدن باشند؛ کافی است در مقابل دستور Disallow هیچ مقداری، قرار ندهید.
از دسترس خارج کردن کل سایت
دقت کنید که علامت “/” در دستور Disallow به معنای “ریشه” و مسیر مادری است که همه صفحات سایت از آن منشعب میشوند. قرارگرفتن علامت “/” دربرابر این دستور نشاندهنده آن است که تمامی صفحات اصلی و صفحات پیوند شده از دسترس رباتهای موتورهای جستجوگر خارج خواهد شد. در این صورت کل سایت از محدوده دید و جستجوی موتورهایی مانند گوگل ناپدید میشود.
دستور “Allow” در فایل robots.txt
همانطور که از نام آن مشخص است؛ با استفاده از دستور “allow” میتوانید یک صفحه مشخص از میان صفحات مسدود شده را در اختیار رباتهای جستجوگر قراردهید. به خاطر داشته باشید که بعضی از موتورهای جستجوگر قابلیت تشخیص این دستور را ندارند.
Crawl-delay در دستورات robots txt
دستور Crawl-delay در فایل robots txt برای جلوگیری از تعداد درخواستهای زیاد توسط رباتها استفاده میشود. وبمسترها با استفاده از این دستور میتوانند به طور دقیق مشخص کنند که میان هر درخواست ربات، چند میلی ثانیه وقفه وجود داشته باشد. دستور نرخ تاخیر بر روی رباتهای گوگل موثر نبوده و برای تنظیم این زمان برای رباتهای گوگل باید به کنسول جستجوی گوگل مراجعه کنید.
پیش از استفاده از دستور Crawl-delay توجه داشته باشید که حجم صفحات سایت شما چقدر بوده و آیا استفاده از این دستور در فایل robots.txt، اقدامی مناسب است؟ گاهی اوقات عدم توجه به این نکات و اعمال این دستور باعث میشود که به سئو سایت آسیب وارد شود.

دسترسی به فایل Sitemap
فایل XML نقشه سایت به رباتها کمک میکند تا از مسیر خزیدن و بررسی خود مطلع شوند. فایل نقشه سایت تنها اطمینان حاصل میکند که رباتها صفحهای را فراموش نخواهند کرد. همچنین این فایلها اولویتبندی برای رباتها تعریف نمیکنند.
فایل robots.txt برای وردپرس
وردپرس نیز دارای یک فایل مجازی از robots.txt بوده که به صورت پیش فرض عمل میکند. برای مشاهده این فایل کافی است در انتهای دامنه اصلی سایت خود عبارت “robots.txt/” را تایپ کرده و جستجو کنید. صفحه باز شده نشاندهنده دستورهای مختلف موجود در فایل مجازی robots.txt است.
اگر قصد ویرایش مقادیر و دستورات این فایل را دارید؛ باید یک فایل متنی با نام robots.txt و حروف کوچک در مسیر اصلی سایت آپلود کنید تا دستورات مورد نظر شما اجرا شود. با آپلود فایل فیزیکی، به صورت خودکار فایل مجازی وردپرس از دسترس خارج خواهد شد.
ساخت فایل robots.txt، اقدامی آسان اما گامی موثر در سئو
robots.txt فایل متنی ساده در مسیر اصلی سایت بوده که نقشه سایت و بخشهای قابل دسترس را برای رباتهای خزنده مشخص میکند. عدم استفاده از این فایل ساده در سایتهایی با ترافیک بالا، میتواند ضررهای جبران ناپذیری برای سئو سایت به همراه داشته باشد؛ بنابراین با آموزش سئو و مطالعه تمامی دستورات و دستورالعملهای فایل robots.txt میتوانید ایندکس شدن سایت خود را بهینه کنید.همچنین میتوانید با مراجعه به صفحه “دوره جامع سئو“ از آموزشهای کاربردی و جذاب ما بهرهمند شوید.
سؤالات متداول
1- فایل Robots.txt چیست؟
✅ فایل Robots.txt درحقیقت یک فایل متنی ساده است که در مسیر اصلی هاست سایت شما یا روت دایرکتوری (Root Directory) قرار میگیرد. در واقع وظیفه این فایل معرفی قسمتهای قابل دسترسی و بخشهای محدود شده برای دسترسی رباتها یا با تعریفی بهتر، خزندگان سطح وب (Web Crawlers) که از سوی گوگل به منظور بررسی و ثبت اطلاعات سایتها ایجاد شده اند میباشد.
2- چرا به فایل robots.txt نیاز دارید؟
✅ Robots.txt فایل ضروری وب سایت شما نیست، اما یک فایل بهینه سازی شده می تواند از چند لحاظ برای سایت شما مفید باشد. نکته مهمتر اینکه، به شما کمک میکند تا بودجه خزش سایت خود را بهینه کنید.
3- در صورت اضافه نکردن فایل Robots.txt چه اتفاقی برای سایت ما رخ میدهد؟
✅ اگر این فایل در فضای هاست سایت شما بارگزاری نشده باشد، خزندگان و رباتهای گوگل امکان دسترسی به تمام صفحات سایت شما را خواهند داشت و قادر هستند تا تمام محتوای سایت شما را ایندکس کنند.



8 نظر در “Robots.txt چیست؟ آشنایی و آموزش ساخت Robots.txt”
تو فایل روبوت ما میتونیم دسترسی ربات ها ب عکس یا فیلم های سایت رو ببنیدیم که ایندکس نشن؟
سلام وقتتون بخیر
بله می تونید
دوست عزیز برای اینکار بسیار دقت کنید
چون کوچکترین اشتباه میتونه سئو سایت رو بهم بریزه
سلام وقتتون بخیر
🙌👍
سلام و درود
من چند روز پیش برای تست جلوی دیس الو اسلش / زدم
الان میبینم که کل سایت از ایندکس در اومده
هرچی دستور ایندکس میزنم درست نمیشه چی کار کنم
سلام وقتتون بخیر
خب شما به متورهای جستجو اینطوری گفتین که ایندکس نکنه سایت رو کافیه فایل ربوتس خودتون رو تصحیح کنید.
خسته نباشید یه سوال داشتم میشه داخل روبوت نقشه سایتم قرار بدیم؟ تاثیر مثبت داره ؟
سلام وقتتون بخیر
بله به گوگل کمک میکنه زودتر پیدا کنه